CollectiveAccess workflow
I've gotten a few emails lately from other library/archive organizations asking about how we use CollectiveAccess, open-source software for digital collections at museums, archives, and libraries. Our Digital Collections at John Jay launched earlier this year and runs on CollectiveAccess. We're really happy with it! Since it's designed for archival-style content from the get-go, there are a lot of really nice library-friendly touches.
For those considering CollectiveAccess, it might be helpful to see what it looks like to use the software. CollectiveAccess takes a good amount of elbow grease to get up and going (more than Omeka, for instance), but the workflows are pretty straightforward once your installation is stable.
Uploading objects to CollectiveAccess
So how exactly do you populate your CollectiveAccess site? First, I'll define a few special words that CollectiveAccess uses:
object: the thing you digitized. E.g., a photograph, a book, a document. Our rule of thumb is that one physical object = one digital object. Each object is of one type...
object type: what category is the thing? This will affect what metadata fields you'll fill in. For instance, our object type "Trial transcript" has fields for "court" and "stenographer's number," which only apply to this object type.
media representation: an uploaded file. One object can have multiple representations. A photograph-type object might have two media representations: scans of the front and back. Or an oral history might have a PDF and several audio clips.
collection: the conceptual group that contains objects. A collection can have multiple objects. Again, our rule of thumb is one physical collection in the archives = one digital collection. Makes it easy! Makes total sense! (Okay, sometimes we fudge a little.) See our list of collections in our Digital Collections.
Note: the workflows below are just how we use the software. Other places may differ. But it's useful to see examples. This also assumes that you're logged into the back end and your metadata schema are good to go.
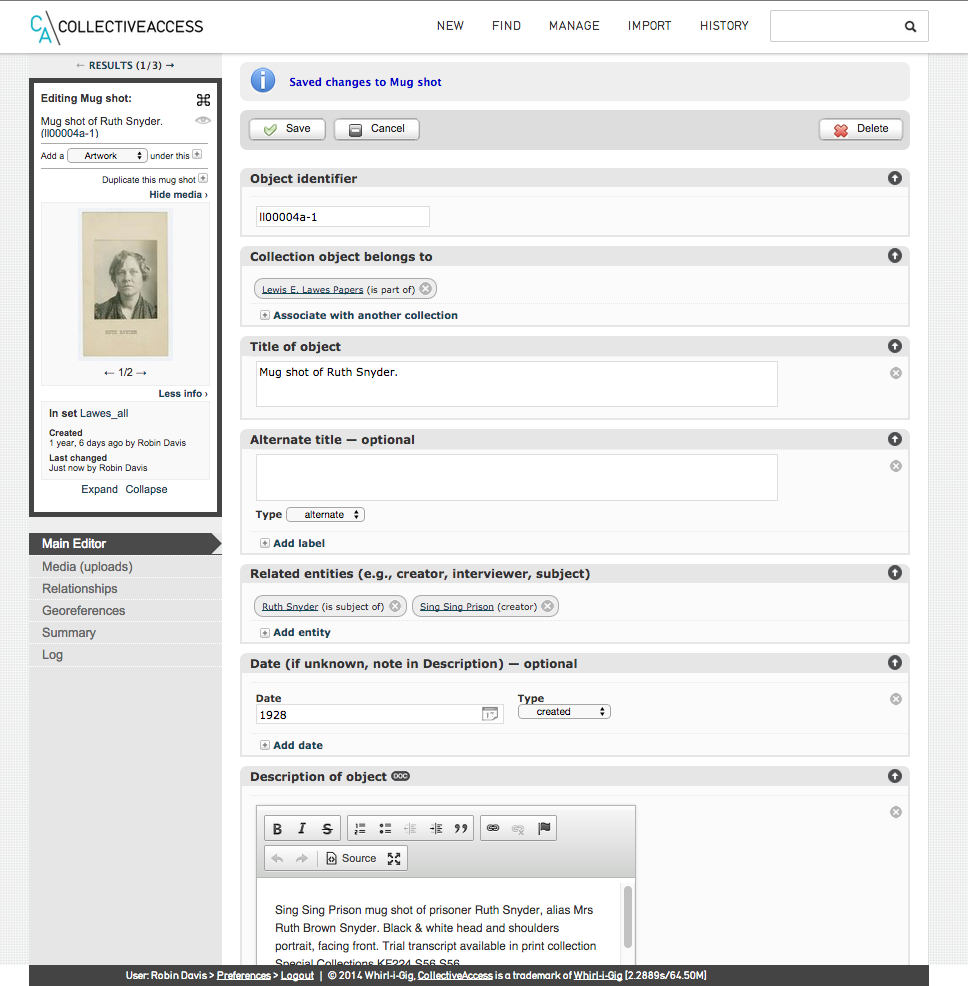
Screenshot of CollectiveAccess, editing a single object (click for larger)
Our workflow for uploading objects one at a time
Example: we had student workers create the John Jay College Archives collection by scanning and inputting metadata, one thing at a time (reviewed later by librarians)
- Click “New object" in CollectiveAccess, choosing appropriate object type
- Write in metadata, either basic or complete, following your organization's conventions
- Upload object (can’t be done first, as uploaded item must have identifier to latch on to, assigned in step 2)
- Review, then make publicly accessible
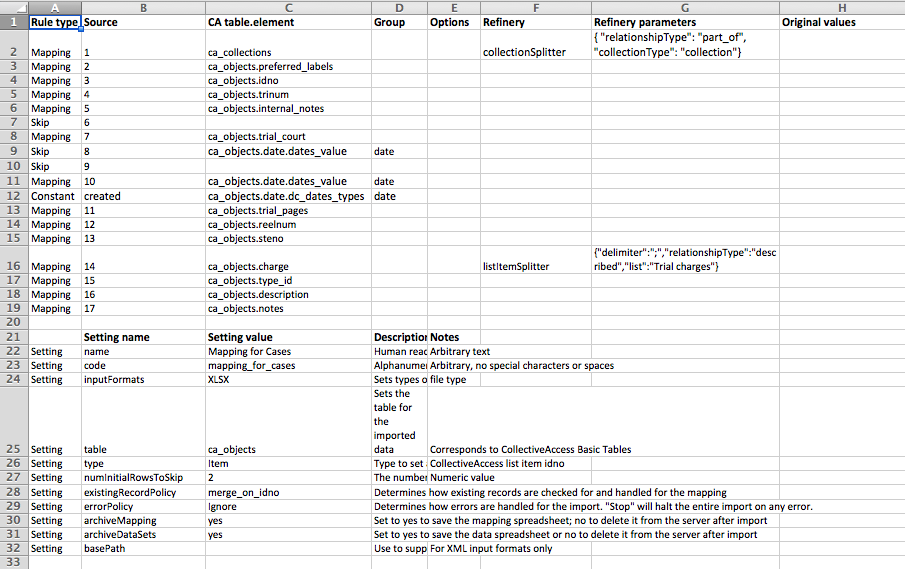
Template for data import in CollectiveAccess. This works in conjunction with another spreadsheet that has metadata related to cases on it. (Click to see larger image, or email me for more example templates)
Our workflow for batch uploads, when we already have all metadata and media files
Example: migrating files and metadata out of an old database, which is what we're currently doing for our trial transcripts collection
- Batch-upload metadata, using the filename as identifier
- data import for CA is complicated to understand at first, but once you get your spreadsheets and templates in order, it's amazing and fast
- this step creates a bunch of objects that don’t have media files attached to them (they're just records)
- you might have to do multiple data imports,to split up big data or because you have complicated data (e.g., we have lots of overlapping person data: defendants, judges, etc.)
- Batch-upload files, matching on filename to existing objects. Takes a while
- Review, then make publicly accessible
When you upload a file to CollectiveAccess, it can take a while because it creates a lot of derivatives. For example, one uploaded photo generates all these files:
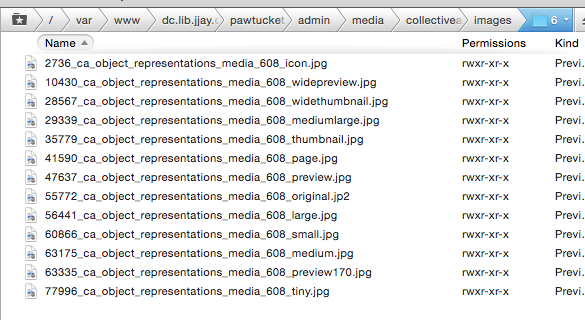
Screenshot of derivative filenames from CollectiveAccess
It also stores the original file, though it's up to you to decide which derivative you allow users to download, if any. Our users can view objects in high resolution (in a special image viewing frame) and download full PDFs, but can only download medium-size JPGs for images. For print quality-size images, a user must contact our Special Collections librarian. This ensures accurate citations.
NYC-area CollectiveAccess events
The CollectiveAccess software is made right here in the city! In September, the friendly CollectiveAccess developers led a workshop at METRO that walked us through configuring new CA installations and importing sample data. The workshop materials are still online and are incredibly useful in piecing together the data import process.
I'm the convener of the CollectiveAccess User Group here in NYC. Our next meeting is Monday, December 1, 2014 at 10am at METRO. We'll get behind-the-scenes tours of CollectiveAccess installations at Brooklyn Navy Yard, Roundabout Theatre Company, Booklyn, and New York Society Library. The CA team attends User Group meetings, too, and is as helpful and responsive in person as they are in the support forums. If you're interested in CollectiveAccess, register for free & join us at METRO!