CollectiveAccess work environment
I wrote earlier about our CollectiveAccess workflow for uploading objects one-by-one and in a batch. Now I'll share our CollectiveAccess work environment. We use two Ubuntu servers, development (test) and production (live), both with CollectiveAccess installed on them. We also use a private GitHub repository.
This is only one example of a CollectiveAccess workflow! See the user-created documentation for more.
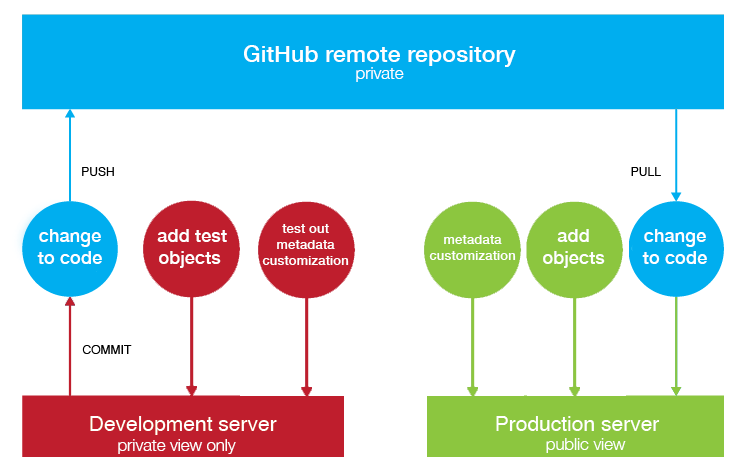
Any changes to code (usually tweaking the layout of front end, Pawtucket) are made first on the dev instance. Once we're happy with the changes and have tested out the site in different browsers, we commit & push the code to our private GitHub repository using Git commands on the command line. Then we pull it down to our production server, where the changes are now publicly viewable.
Any changes to objects (uploading or updating objects, collections, etc.) are made directly in the production instance. We never touch the database directly, only through the admin dashboard (Providence). These data changes aren't done in the dev instance; we only have ~300 objects in the dev server, as more would take up too much room, and there's no real reason why we should have all our objects on the dev instance. But if there's a new filetype we're uploading for the first time, or another reason an object might be funky, we add the object as a test object to the dev server.
Any changes to metadata display (adding a new field in the records) is done through the admin dashboard. I might first try the change on the dev instance, but not necessarily.
Pros of this configuration:
- code changes aren't live immediately and there is a structure for testing
- all code changes can be reverted if they break the site
- code change documentation is built into the workflow (Git)
- objects and metadata are immediately visible to the public
- faculty/staff working on the collections only don't need to know anything about Git
Cons:
- increasing mismatch between the dev and production instances' objects and metadata display (in the future, we might do a batch import/upload if we need to)
- this workflow has no contact with the CollectiveAccess GitHub, so updates aren't simply pulled, but rather manually downloaded
Not pictured or mentioned above: our servers are backed up on a regular basis, on- and off-site; and anytime there's a big code update, a snapshot is taken of the database.
CollectiveAccess super user? Add your workflow to the Sample Workflows page!